Janus Pro 7Bをオンラインで体験
DeepSeekの最先端Janus Pro AIで画像生成とマルチモーダルタスクを試してください。1Bと7Bバージョンが利用可能で、インストール不要です。
Janus Pro 7Bの機能
革新的な技術で画像生成とAI理解の新基準を確立
最先端のパフォーマンス
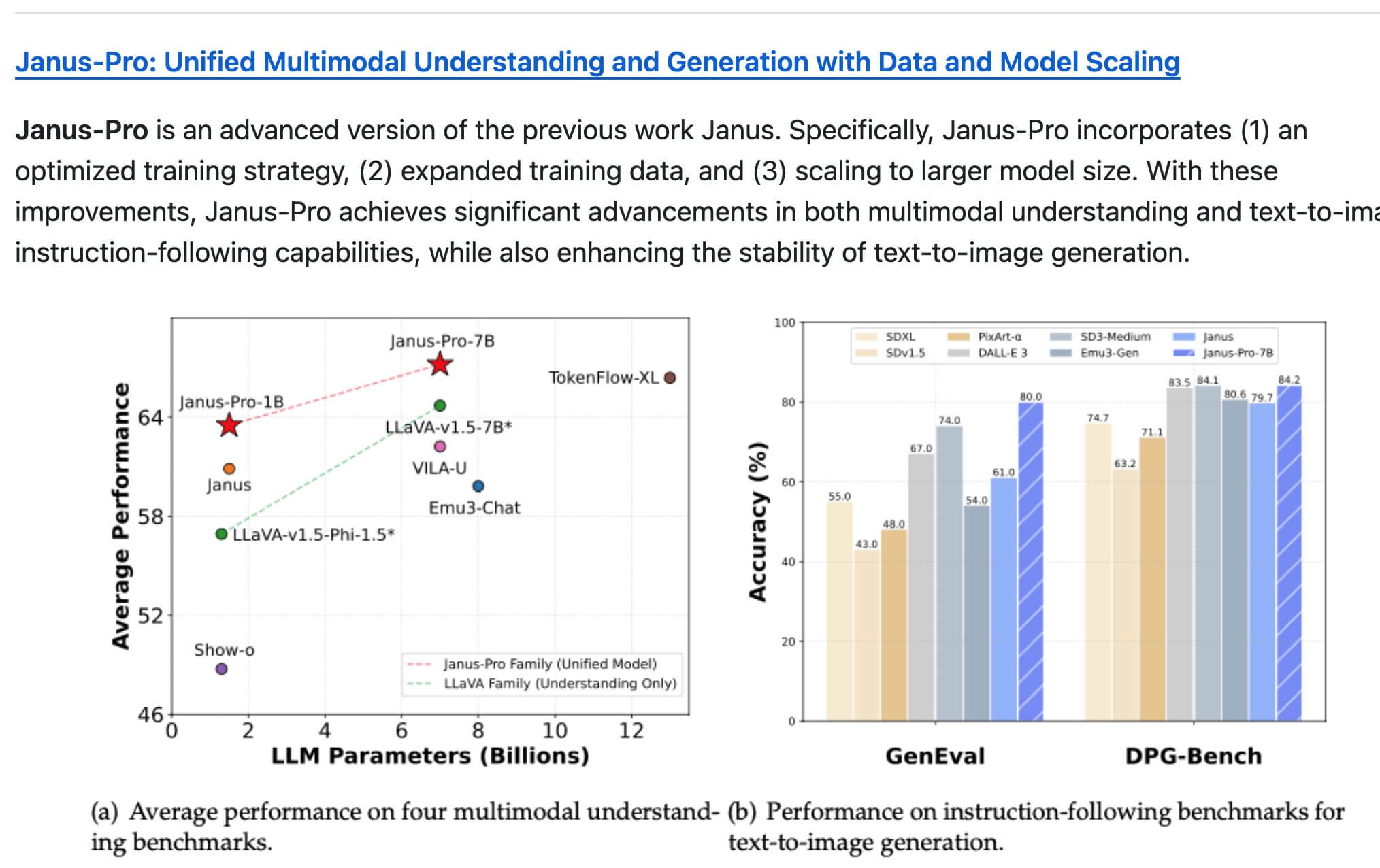
DPG-Benchで84.2%の精度を達成し、DALL-E 3を上回る画像生成の新基準を確立
WebGPUサポート
WebGPUを通じてローカルで実行可能な初のオープンソース画像生成モデル
エンタープライズAPI
企業要件を満たす堅牢でスケーラブルなAPI
DeepSeek Janus-Pro:技術的洞察と使用ガイド
画像理解と生成を統一アーキテクチャで組み合わせた革新的なオープンソースマルチモーダルモデルについて学ぶ
Janus-Proのアーキテクチャの特徴は何ですか?
Janus-Proは、3つの主要コンポーネントを持つデカップルドビジョンエンコーディングフレームワークを採用しています:1) 意味理解のためのSigLIPエンコーダー、2) 整流フローによる効率的な画像生成のためのVQトークナイザー、3) テキスト/画像埋め込みを処理する7Bパラメータのバックボーン。このアーキテクチャは、マルチモーダル理解で79.2 MMBench精度、画像生成で0.80 GenEvalスコアを達成しています。
MidJourneyやStable Diffusionと比較してJanus-Proはどうですか?
Janus-Proには独自の利点があります:1) 商用利用が自由なMITライセンス、2) 理解と生成の両方に対応する統一アーキテクチャ、3) DALL-E 3(0.67)やSD3-Medium(0.74)を上回る0.80 GenEvalスコア。ただし、現在の出力解像度は384×384で、競合製品の1024×1024と比べて低くなっています。
Janus-Proのインストールオプションは何がありますか?
主に2つのインストールオプションがあります:1) ComfyUI統合(UIワークフロー向け推奨)- ComfyUI-Janus-Proプラグインをインストールし、Hugging Faceからモデルファイルをダウンロード、2) ローカルデプロイメント(上級ユーザー向け)- 1x RTX A6000 GPU、64GB RAM、100GB ストレージが必要。GitHubリポジトリをクローンしてデモアプリケーションを実行します。
Janus-Proを実行するためのハードウェア要件は何ですか?
最適なパフォーマンスを得るには、Janus-Proは以下が必要です:1x RTX A6000 GPUまたは同等品、64GB RAM、100GBストレージ。モデルは7Bと1Bパラメータの2つのバージョンがあり、1Bバージョンはハードウェア要件が低く、合理的なパフォーマンスを維持しています。
Janus-Proの主な長所と制限は何ですか?
長所:1) 統一アーキテクチャによるデプロイメントの複雑さの軽減、2) ベンチマークでSD3-MediumとDALL-E 3を上回る性能、3) MITライセンスによる商用の自由。制限:1) 競合製品と比べて低い解像度(384px)、2) ローカルデプロイメントに技術的な専門知識が必要。
Janus-Proをニーズに合わせてカスタマイズするにはどうすればよいですか?
Janus-Proは多言語入力をサポートし、美的効果とアライメントを改善するために合成データを使用して微調整できます。MITライセンスの下でオープンソース化されており、広範なカスタマイズと既存のワークフローへの統合が可能です。
Janus-Proの将来の展望はどうですか?
現在は写真のリアリズムで劣るものの、Janus-Proのスケーラブルなアーキテクチャ(7B vs 以前の1.5B)と合成データトレーニングは、急速な改善の可能性を示唆しています。コストと柔軟性がピクセル密度の要件よりも重要な統合ビジョン言語パイプラインに最適です。
ワークフロープロセスはどのように機能しますか?
Janus-Proは多言語のテキストプロンプトを受け付け、384×384pxの画像またはテキスト説明を出力します。ワークフローはComfyUIインターフェースまたはAPIコールを通じてカスタマイズでき、出力品質を向上させるために合成データを使用して微調整することができます。